Reserved GPUs March 2026
Carmen Li
Table of Content
H100, H200 & B200: Supply Constraints, Pricing Shifts, and What Smart Teams Are Doing Now
Billions of dollars are pouring into AI infrastructure in 2026, and GPU availability is tighter than ever. The numbers tell a contradictory story: the data center GPU market has exploded to nearly $48.39 billion, hyperscalers have committed over $450 billion to AI infrastructure, and yet teams across the industry are struggling to secure the compute they need at prices that make economic sense.
The March pricing data in the uploaded CSV already shows how fragile headline GPU pricing can be. (For background on how GPU marketplaces have evolved and why pricing fragmentation is structural, see our deep dive.) Looking only at reserved rows, H100 listings span about $1.07 to $10.14 per hour (median $5.52), H200 about $1.85 to $10.79 (median $5.82), and B200 about $2.65 to $10.92 (median $9.10). This is not a uniform commodity market. Even within one month of listings, provider class, GPU configuration, and country materially change the clearing price.
This article is a March 2026 snapshot of where GPU pricing, supply, and strategy stand right now across the three GPUs that matter most: H100, H200, and B200. The uploaded CSV includes reserved, on-demand, and spot rows; unless noted otherwise, the pricing discussion below isolates the reserved subset because it is the cleanest like-for-like view of committed capacity. (For a primer on how reserved and on-demand models compare at a strategic level, start there.) We will walk through why supply constraints persist, what the pricing landscape actually looks like, and what the most effective procurement strategies are for teams operating under real operational pressure.
Why Supply Is Still the Story
The headline number: AI now consumes approximately 70% of global DRAM production. That single statistic explains more about the GPU market in 2026 than any other data point. The supply constraints facing GPU buyers are not temporary disruptions. They are structural bottlenecks with 18 to 24 month lag times between investment and production.
The HBM Memory Bottleneck
High Bandwidth Memory has become the defining constraint for the AI market. Based on Q3 earnings calls from SK Hynix, Micron, and Samsung, HBM supply is fully allocated through 2026, with early signals suggesting tightness could extend into 2027. The scale of demand is staggering: a single next-generation NVIDIA B300 GPU requires 96 individual DRAM dies for its HBM modules alone. A fully configured DGX B300 system with eight GPUs consumes 768 DRAM dies just for HBM, not counting system memory.
Memory manufacturers have responded by reallocating production capacity from consumer electronics toward AI infrastructure. Hyperscale cloud providers including Meta, Google, Microsoft, and Amazon have signed long-term supply agreements that effectively lock up production capacity at premium prices for years, leaving mid-market buyers to compete for whatever remains.
CoWoS Packaging and Manufacturing Constraints
TSMC’s advanced packaging process, CoWoS (Chip-on-Wafer-on-Substrate), underpins nearly all high-end AI accelerators. TSMC executives have been unusually direct about the situation: advanced-node wafer demand is currently about three times greater than their available capacity. CoWoS capacity remains sold out through 2025 and into 2026. Even with record capital expenditure, ramping new nodes takes years, not quarters.
Power and Cooling as the Next Bottleneck
The B200’s 1,000-watt thermal design power makes liquid cooling mandatory, not optional. This creates an infrastructure barrier that limits how fast new GPU capacity can come online. A single large-scale Blackwell cluster of one million GPUs would consume an estimated 1.0 to 1.4 gigawatts of power, enough to sustain a mid-sized city. Data centers that lack liquid cooling infrastructure simply cannot deploy B200 hardware, regardless of whether they can secure allocation.
The takeaway: these are not temporary disruptions that will resolve within a quarter or two. The 18 to 24 month gap between capacity commitment and volume production means that the constraints shaping the market today will persist well into 2027.
GPU-by-GPU: Pricing, Availability, and Best Fit
Understanding the current state of each major GPU generation is essential for making informed reservation decisions. Each occupies a distinct position in the market with different pricing dynamics, availability profiles, and ideal use cases.
H100: The Volatile Workhorse
The H100 remains the mainstream high-end GPU for AI workloads in 2026, and the uploaded March CSV shows persistent market fragmentation. Across reserved H100 rows, prices run from about $1.07 to $10.14 per hour, with a median of $5.52. Marketplace H100 median is $1.70, neocloud median $2.31, and hyperscaler median $6.11, so the hyperscaler median is roughly 3.3x the combined non-hyperscaler median. That is not a rounding error.
What makes H100 notable is not just the low-end price. It is the lack of convergence. Configuration still matters: in the reserved sample, H100 PCIe variants carry median prices around $1.54 to $2.05, while SXM and NVL variants sit closer to $5.47 to $5.98. Mature demand for inference, fine-tuning, and production training still supports materially different price points across the same family.
Secondary supply has not eliminated that dispersion. In the uploaded March CSV, marketplace H100 rows cluster around the high-$1s, neocloud rows in the low-$2s, and hyperscaler rows in the low-$6s on a median basis. Buyers who treat 'H100 price' as a single number are still likely to misprice capacity.
Reserved pricing: in this March reserved sample, marketplace H100 rows run about $1.07 to $2.36 per hour, neocloud $1.35 to $3.02, and hyperscaler $2.58 to $10.14.
Best fit: Production inference, balanced training workloads, fine-tuning runs, and teams that need the broadest provider and tooling ecosystem. For a deeper look at the H100's architecture and how it stacks up against the A100, see our A100 vs. H100 guide.
H200: The Bridge Generation
The H200 occupies a strategic middle ground between the mature H100 and the next-generation B200. With 128 to 141 GB of HBM3e memory and significantly improved bandwidth over the H100, it delivers meaningful performance gains for memory-bound workloads without requiring the infrastructure overhaul that B200 demands.
Availability is notably better than B200 across many providers. In the March reserved sample, H200 listings run about $1.85 to $10.79 per hour overall, with a median of $5.82. The family itself splits sharply by configuration: H200 NVL 141GB has a $2.25 median in the reserved rows, versus $6.12 for H200 SXM 141GB.
On a median-price basis in this March reserved sample, H200 sits about 32% to 51% below B200 depending on provider class. Marketplace H200 median is $2.45, neocloud $3.13, and hyperscaler $6.80, which keeps H200 in a meaningful middle band between H100 and B200. That remains attractive for teams that need more memory without stepping all the way into Blackwell pricing.
Best fit: Teams needing a meaningful upgrade from H100 without committing to liquid-cooled infrastructure. Ideal for moderate-scale training, large inference workloads, and organizations planning a phased transition to Blackwell. Our H100 vs. H200 comparison breaks down the architectural differences and when the memory upgrade justifies the cost.
B200 (Blackwell): The Future, If You Can Get It
The B200 represents a full generational leap in GPU architecture. Built on NVIDIA’s Blackwell platform, it packs 208 billion transistors across two dies, delivers 192 GB of HBM3e memory with 8 TB/s bandwidth, and achieves 20 petaFLOPS of FP4 compute. The second-generation Transformer Engine with native FP4 arithmetic means that models requiring 8 GPUs on H100 can potentially run on 2 to 4 B200s.
The catch is availability. Blackwell B200 and GB200 units were reported sold out through mid-2026 as of late 2025, with backlogs reaching 3.6 million units. Any enterprise looking to build frontier-scale AI models today faces potential wait times of 18 months or more, or must settle for previous-generation Hopper hardware.
Reserved pricing in the March dataset runs from about $2.65 to $10.92 per hour for B200, with a $9.10 median. Marketplace B200 rows span roughly $2.65 to $10.00, neocloud $4.30 to $4.91, and hyperscaler $9.10 to $10.92. In this CSV, B200 pricing dispersion is driven less by configuration than by provider class and country.
Best fit: Teams building new infrastructure for the 2026 to 2028 cycle, frontier-scale model training, and organizations that need maximum compute density. Not the right choice if budget is the primary constraint or existing air-cooled facilities cannot be upgraded.
GPU Comparison at a Glance
GPU | Reserved $/hr | Coverage | Memory | Best Fit Use Case |
H100 family | $1.07-$10.14 | Reserved | 64-94 GB | Production inference, fine-tuning, balanced training |
H200 family | $1.85-$10.79 | Reserved | 141 GB | Mid-scale training, large inference, bridge to Blackwell |
B200 | $2.65-$10.92 | Reserved | 192 GB | Frontier training, max compute density, new infra builds |
Sources: uploaded March GPU rental CSV. The full file contains 10,783 rows dated March 1-24, 2026: 2,736 reserved, 5,049 on-demand, and 2,998 spot. The comparison table above uses the reserved subset only.
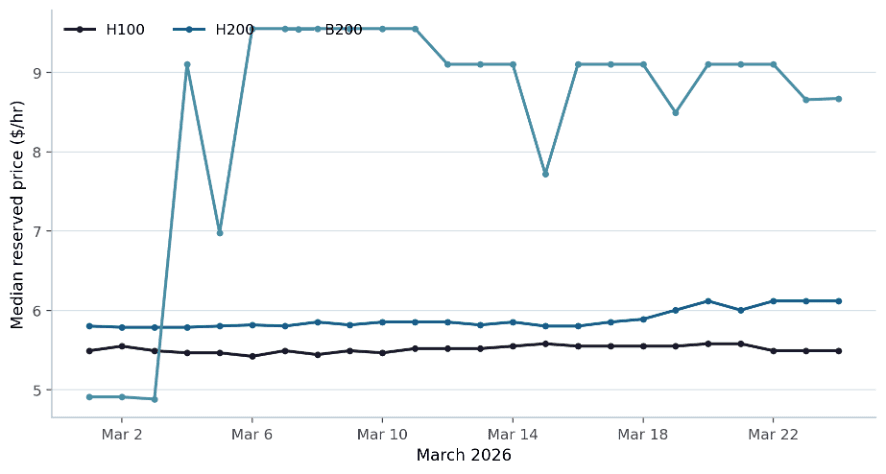
Figure 1. Daily median reserved price from the uploaded CSV (reserved rows only). H100 and H200 medians were comparatively stable through March, while B200 reset sharply upward after the first week.
The chart reinforces the main procurement lesson from the table above: even when family-level medians look stable, a buyer can still move between very different price bands once provider class and configuration enter the negotiation.
The Reserved Pricing Landscape
Price discovery for GPU compute remains, in Silicon Data’s words, “profoundly challenging.” This is not a transparent commodity market. Cloud providers, specialized GPU clouds, decentralized marketplaces, and resale platforms all operate with different cost structures, service levels, and target customers. The fragmentation is both the problem and the opportunity.
Reserved Instances: Wide Dispersion Even Within One Month
The uploaded March CSV includes on-demand, reserved, and spot rows, but the cleanest apples-to-apples comparison for committed capacity is still the reserved subset. Within those 2,736 reserved observations, H100 spans about $1.07 to $10.14 per hour, H200 $1.85 to $10.79, and B200 $2.65 to $10.92. The practical takeaway is that reservation strategy is not just about commitment length. It is about choosing the right provider class and configuration before you lock in the rate.
However, lower hourly rates do not always translate to lower total spend. The critical metric is cost per productive hour, not cost per hour — a point we explore in detail in our reserved vs. on-demand GPU guide. A startup reserving 16 H100s for 6 months at a compelling rate but running them at 50% utilization is effectively paying double. Smart teams in 2026 model utilization patterns before committing, targeting a minimum of 60 to 70% utilization to justify reservation economics.
Provider Class Drives the Largest Reserved Premiums
In this March reserved sample, hyperscaler premiums are clearly visible in the medians. Relative to combined non-hyperscaler alternatives, hyperscaler H100 is about 3.3x higher, H200 about 2.7x, and B200 about 2.2x. The premium is still material, but the exact multiple depends on the GPU, configuration, and seller mix.
Table 1. Median reserved hourly price by provider class from the uploaded CSV.
GPU family | Marketplace | Neocloud | Hyperscaler |
|---|---|---|---|
H100 | $1.70 | $2.31 | $6.11 |
H200 | $2.45 | $3.13 | $6.80 |
B200 | $4.98 | $4.58 | $10.47 |
Spot Pricing Is in the CSV, but Should Be Modeled Separately
The uploaded CSV also contains 2,998 spot rows, but those benchmarks should not be blended into the reserved ranges above. Interruption risk, checkpoint frequency, and eviction policy change the true economics of spot capacity, so spot should be treated as a separate procurement track rather than a direct substitute for reserved commitments.
Country Codes Help, but Cloud-Region Granularity Is Still Missing
The March CSV does include country codes, so high-level cross-country comparisons are possible. What it does not include is standardized cloud-region or availability-zone metadata, so fine-grained geographic arbitrage still needs supplemental provider data.
What Smart Teams Are Doing Right Now
The most effective procurement strategies we see in 2026 are not single-model bets. They are portfolio approaches that match commitment depth to workload predictability.
Hybrid Procurement
Reserve 60 to 70% of anticipated peak capacity for baseline workloads, then use more flexible channels for everything else. The March reserved sample shows why benchmarking matters: the H100 family alone spans about $1.07 to $10.14 per hour depending on provider class and configuration. Teams that compare broadly before committing reduce the odds of locking in the wrong baseline price.
Generation Planning
Not every workload needs the latest hardware. In this March reserved sample, marketplace and neocloud H100 rows generally land between about $1.07 and $3.02 per hour and still cover most inference and fine-tuning workloads efficiently. B200 reserved listings start meaningfully higher on a median basis, so they make sense only when you genuinely need the added compute density or are building new infrastructure for the 2026 to 2028 cycle.
Geographic Arbitrage
For non-latency-sensitive workloads, deploying in lower-cost regions delivers meaningful savings. This is not about finding the absolute cheapest option. It is about matching region selection to workload requirements, factoring in provisioning delays, data residency considerations, and energy costs alongside the headline GPU rate.
Contract Flexibility
The market has evolved past rigid multi-year lock-ins. Providers now offer 3, 6, and 12-month reservation options, flexible upgrade paths to newer hardware mid-term, credit portability across regions, and in some cases, secondary market resale of unused capacity. Look for transferable and convertible clauses that de-risk longer commitments.
Multi-Vendor Comparison
Stop negotiating bilaterally with a single provider. In a market where provider-class median prices still differ by roughly 2x to 3x, benchmarking across vendors is not optional. It is the difference between overpaying and making an informed procurement decision. Our overview of reserved GPU marketplaces covers the full provider landscape, pricing structures, and reliability metrics across hyperscalers and neoclouds.
What’s Coming Next
Several developments on the horizon will reshape the reserved GPU landscape over the next 6 to 12 months.
Vera Rubin (H2 2026): NVIDIA’s next-generation platform promises 50 petaFLOPS of NVFP4 inference capability with 288 GB HBM4 memory at an estimated 10x lower cost per token than Blackwell. If delivered on schedule, this represents the next major pricing reset for reserved GPU capacity.
Expiring H100 contracts: Multi-year H100 deals signed in 2024 are beginning to unwind at scale. This should return inventory to the market, but as we have already seen, demand is absorbing returning supply faster than expected. Price relief is not guaranteed.
HBM4 transition: The shift to HBM4 memory could ease or worsen the memory bottleneck depending on ramp speed. SK Hynix has indicated that the DRAM market is expected to remain in shortage throughout 2026, especially for high-end products.
AMD MI355/MI455X: Meaningful alternative supply is emerging, but NVIDIA still dominates reserved capacity channels. Teams willing to adapt their software stack may find competitive pricing on AMD hardware. For a broader view of how GPU marketplaces are evolving to accommodate these shifts, see The Rise of GPU Marketplaces in 2026.
The structural reality: capacity commitments made today do not produce chips until 2027 or 2028. The 18 to 24 month production lag means the constraints shaping the market right now will persist regardless of how much capital is deployed. Teams that secure favorable reserved capacity today are positioning themselves ahead of a supply curve that will not catch up to demand for at least another 12 to 18 months.
Find the Right GPU Compute with Compute Exchange
In a market where provider-class median prices still differ by roughly 2x to 3x—and row-level ranges are much wider—procurement strategy has become a competitive advantage.
Compute Exchange operates as a marketplace that connects GPU buyers with providers across the full spectrum of reserved, on-demand, and spot pricing models. Instead of checking five provider dashboards and manually comparing pricing, availability, and terms, you submit your compute requirements once and the platform surfaces competitive options across multiple vendors, regions, and GPU generations.
Submit your compute requirements to Compute Exchange today and see what competitive reserved GPU options look like across the full market, not just the two or three providers you already have relationships with.
Is this fully AI or fully human?
Is this fully AI or fully human?
Is this fully AI or fully human?
The Compute Exchange Is Now SOC 2 Type II Compliant

Jason Cornick
Jun 5, 2026

NVIDIA H100 GPU Price in 2026: New, Refurbished, and Used

Carmen Li
Apr 24, 2026
Reserved GPUs Contract Length: A Complete 2026 Buyer’s Guide
Carmen Li
Apr 10, 2026
Reserved GPUs March 2026
Carmen Li
Mar 26, 2026
Reserved GPU Marketplaces
Carmen Li
Mar 4, 2026
The Rise of GPU Marketplaces in 2026
Carmen Li
Feb 23, 2026
H100 vs. H200:Choosing the Right NVIDIA GPU for AI Workloads
Carmen Li
Feb 5, 2026
[Case Study] How Modular Secures Reserved GPU Capacity
Carmen Li
Jan 15, 2026

Reserved vs. On-Demand GPU in 2026
Carmen Li, CEO at Compute Exchange
Jan 5, 2026

A100 vs. H100: A 2026 Guide to Choosing the Right NVIDIA GPU

David King
Dec 21, 2025

Best GPU Rental Platforms in 2026: A Buyer's Comparison

Dmytro Lokshyn
Jun 12, 2026